Ask any enterprise data science team what slows them down, and you'll probably hear similar...
By Gaël Varoquaux, CSO of Probabl & Research Director at Inria
Data science is not AI. But without it, modern AI would not exist; and without the statistical thinking that is at the core of data science, the AI systems being deployed today will keep failing in ways that are entirely predictable and entirely avoidable.
What I call data science is the art or the science of using data to build better models and produce better insights. It’s used everywhere from healthcare to optimizing manufacturing, product recommendations, or logistics in retail. The same processes also led to building today’s image or language models.
There is a tendency to talk about data science as if it were a practice of software engineering. That framing misses what actually makes it hard, and what makes it indispensable in AI. The difficult part is not the coding. It's statistical thinking: knowing when your data is lying to you, understanding what your model can and cannot generalize, and reasoning carefully about cause and effect.
Behind every impressive model is a chain of decisions that are not about model architecture, but about what to measure, how to collect it, whether the data can be trusted, and whether the predictions actually support the decisions they are meant to inform.
As we move toward a world of AI agents operating on real data with real consequences, getting these questions right is not optional and in many cases non-negotiable. In a recent keynote, I argued that data science – not as an engineering practice, but as a statistical discipline – is the foundation AI is built on and the frontier where its limits will be pushed.
Statistical thinking is the heart of AI
The headline successes of AI like generating images and text, understanding speech, and proving mathematical theorems look, on the surface, like feats of engineering and scale. Yet under the hood, they are all deeply statistical. The reason is that AI doesn't solve problems the way a deterministic algorithm does. It finds continuities. It interpolates and extrapolates. By embedding discrete objects – words, symbols, logical constructs – into continuous geometric spaces, it endows them with a metric. That metric is what allows a model to build predictive functions that generalize across things it has never seen before.
But statistics alone does not explain why AI succeeds where rule-based systems failed. To understand that, we need to look at what makes the real world so resistant to clean, deterministic description.
Ambiguity is everywhere. The challenge for AI is that the world is full of ambiguity. Context is key. For example, a river bank and the Bank of America share a word but nothing else. And disambiguation only goes so far; for instance ambiguity might be intrinsic to a statement, as in “fruit flies like a banana, time flies like an arrow”. Fundamentally, I don’t believe a finite system of rules, curation, or normalization can fully capture a world this messy.
Categories shape what we can know, and they’re full of arbitrariness. We create categories to simplify the messiness of the world. But there is also arbitrariness in our categorization and this has implications for how we know and understand the world. To take just one example, consider the many different titles for professors that exist in different countries: Junior Professor, Adjunct Professor, Assistant Professor, Tenured Track, Senior Lecturer, Reader, Maître de conférence, Chargé de Recherche, HDR, Universitätsprofessur, Assistenzprofessur, S-Professur, Científico Titular, Profesor Ayudante Doctor, Profesor Colaborador, Profesor Agregado, and 兼职教授, among many others. None of these titles map cleanly onto each other, yet any dataset that includes academic seniority must pick one schema and that choice shapes every analysis built on top of it. As the late Alain Desrosières argued, “A system of categories ends up shaping the world because the world needs to conform to it and because it grounds our measurements.”
LLMs are a double-edged sword for dealing with fuzziness. This is precisely the challenge that LLMs must navigate. An LLM builds a consistent view across misaligned references and schemas, contradictory information, and unquantified uncertainties. The messiness of human knowledge gets compressed into a single model. Its limited memory forces a lossy compression, and this compression can lead to errors, often called hallucinations. For example, ask an LLM for a short biography of Albert Einstein and some of what it returns will be well-established fact, some will be plausible-but-uncertain, and some will simply be wrong with nothing in the output to tell you which is which. At scale, across millions of queries on topics far less well-documented than Einstein, this becomes a serious problem. What we need is a form of confidence: a way for the model to signal not just what it believes, but how much it should be believed.

Figure 1: Example of LLM-generated output about Albert Einstein, labelled by confidence level.
Source: https://arxiv.org/abs/2402.04957
The problem of errors and confidence
This picture immediately raises a practical concern: if AI outputs are probabilistic summaries of noisy, heterogeneous training data, how do we know when to trust them? A simple answer is calibration – the property that when a model says it is 80% confident, it should be right about 80% of the time. In short, calibration is a statistical tool we can wield to control the probability of an AI's output given its input.
Controlling uncertainty needs to go beyond calibration. Calibration alone is not sufficient, as my colleagues and I show why in our paper, “Reconfidencing LLMs from the Grouping Loss Perspective” [1]. We constructed an evaluation dataset derived from the YAGO knowledge base [2] to assess the confidence scores given by Mistral 7B and LLaMA 7B on factual questions about things like birth dates, founders of companies, and composers of songs. The models tended to be systematically overconfident, but not uniformly so. When we looked at the overall calibration curve, the picture looked reasonable – the models’ expressed confidence tracked its actual accuracy fairly well on average.
Calibration curves can mask disparities by group. The aggregate picture we got from the overall calibration curve masked disparities underneath, as shown in Figure 2. Splitting by entity popularity, answers about well-known figures were far better calibrated than answers about long-tail entities. And splitting by nationality, the model was reasonably calibrated for questions about Americans and French people, but performed dismally for Indian and Chinese individuals – near-zero accuracy even when expressing high confidence.
This is why grouping loss matters. In uncertainty-quantification theory, this is called grouping loss [3] – a model's overall calibration error may appear small, but its confidence scores can deviate catastrophically from true posterior probabilities for specific subgroups. A well-calibrated model on average can still be biased; for example, it can generate untruthful information with high confidence about particular nationalities, genders, or other minority groups. Standard calibration techniques, which focus on average performance, cannot fix this because errors in one subgroup are masked by accuracy in another. It is worth noting that this is not merely a calibration failure. It is a window into the social structure of model errors. The training data is not a neutral sample of the world. It reflects the over-representation of certain languages, institutions, and knowledge traditions. Statistical methods are what let us detect and reason about these failures.
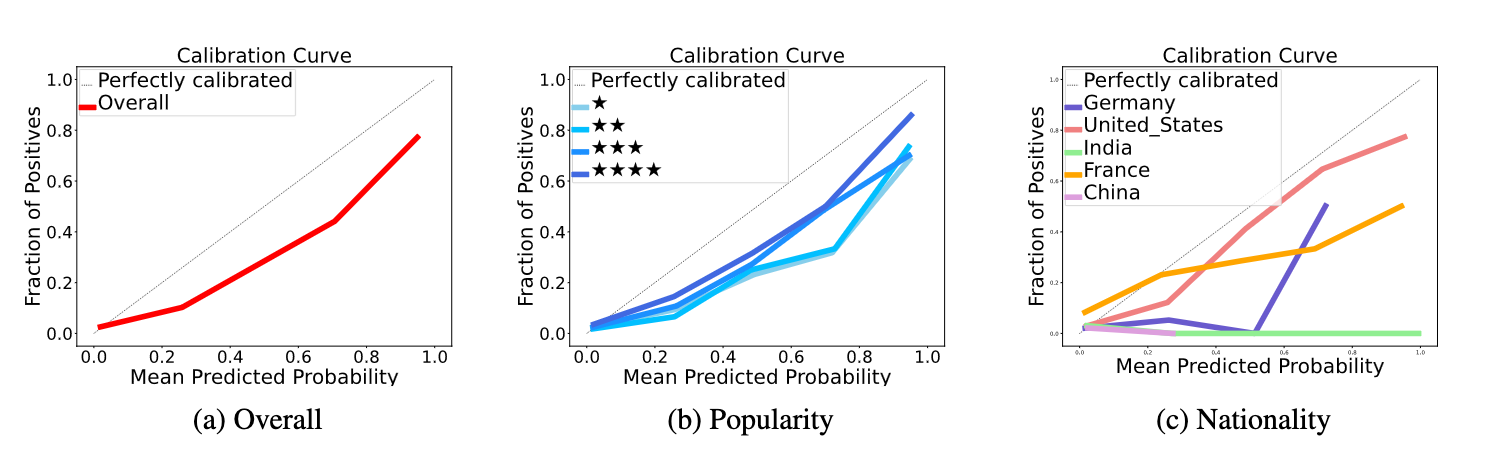
Figure 2: Calibration curves of the Birth_Date relation, using Mistral-7B and SelfCheckGPT to compute confidence scores. An increased number of symbols signifies a sub-group containing more popular samples.
Source: https://arxiv.org/abs/2402.04957
The science of data science
This brings me to a point that’s close to my heart: data science as a scientific discipline.
Data science is not a practice of software engineering. As I mentioned at the beginning, there is a tendency to view data science as a practice of software engineering but that framing misses what actually makes it hard and what makes it indispensable in AI. What I call data science is the art or the science of using data to build better models and produce better insights.
Data science is the practice of building processes from statistical thinking and empirical evidence. Machine learning sits at its center of it because it allows us to automate problems that we do not yet know how to specify by hand. The applications are everywhere: optimizing industrial processes, detecting credit card fraud, evaluating health risk, predicting flight delays, catching cyberattacks, and so on. This is the world of tabular AI – high-value and deeply statistical.
Aleatoric versus epistemic errors
At its mathematical core, the task in data science is straightforward: given paired data (x, y), learn a function f such that f(x) ≈ y. Under a quadratic loss, the target is the conditional expectation E[y|x]. The challenge is estimating that expectation well from finite, imperfect data.
The deeper challenge is that the data we have is rarely the data we need, and the errors that result are not all the same kind. Not every prediction failure is fixable by getting more data or training a bigger model. Statistics makes a crucial distinction here between aleatoric and epistemic errors.
Aleatoric errors. Aleatoric error is the intrinsic randomness in the data itself. Some things simply cannot be predicted from the available inputs. Data science problems, particularly in healthcare and human behavior, are full of aleatoric errors. Other AI domains like playing Go or understanding images have less.
Epistemic errors. Epistemic errors concern modeling imperfection – that is, the gap between what our model learns and the best possible prediction. It shrinks, in principle, with more data and better models.
Practically, predictable structure in a model's errors is a signature of epistemic error. For example, if errors cluster by nationality, hospital, or time period, those patterns tell you the model can still be improved. If errors look random given the inputs, you have probably hit the aleatoric floor, and the right decision is to collect different data, not train longer. This is the subject of my ongoing work with Sébastien Melo, Marine Le Morvan, and Alexandre Perez-Lebel [4].
Are powerful models and big data all we need?
A crucial lesson from data science is that the data available to train a model are almost never the data we actually need.
Covariate shifts. In the benign case, we are confronted with the problem of a covariate shift – that is, when the distribution of inputs changes between a model's training and deployment, but the underlying relationship between x and y is preserved. A sufficiently flexible model trained on enough data can handle this.
Selection bias. Far more dangerous is selection bias that distorts the association between x and y. When data are selected on a mechanism that is a common cause of both the input and the output, the learned function becomes systematically wrong. More data, bigger models, and better architectures will not fix this. In this case, the problem is not in the model; it’s in the data-generating process.
Causal reasoning matters when predictions guide actions
A frequent and challenging cause of data shift is when the purpose of a model is not just to predict but to guide action.
Consider a model trained to predict patient outcomes as a function of health covariates. A standard risk minimizer, trained on observational data, will learn that treated patients tend to have worse outcomes because in the real world, only sick patients receive treatment. The model correctly describes the observational data. But if used to guide treatment decisions, it will systematically recommend against treating the people who may need it most.
Causal reasoning. What we actually need in this case is the causal effect of the intervention: E[Y₁(x)] − E[Y₀(x)], the difference between outcomes under treatment and outcomes without it, as a function of patient covariates. This requires reasoning about extrapolation into regions of the feature space that are not represented in the training data – healthy people who were never treated, sick people who never received the alternative. The extrapolation is precisely what matters. This is not a machine learning problem. It is a data science problem, requiring statistical reasoning throughout the data-generating process.
Validation is a bottleneck for trustworthy, production-ready models
Even setting aside distribution shifts and causal questions, the most elementary requirement of responsible machine learning – honest evaluation – turns out to be harder than it looks.
The golden rule of evaluation. The golden rule is simple: evaluate models on data they have not been trained on. In practice, this means train/test splits at minimum, cross-validation for more robust estimates, temporal splits for time-dependent data, and out-of-distribution evaluation to stress-test generalization.
Why mitigating data leakage is crucial. A pervasive pitfall in machine learning pipelines is data leakage – when information from the test data contaminates the training data, often through preprocessing steps that should have been fit only on training data. When this happens, performance metrics become misleading and models that look good in development fail in production [5].
Choosing the right metric matters as much as choosing the right model. Accuracy is simple but misleading on imbalanced problems and has poor statistical properties. Proper scoring rules such as the Brier score – which penalizes both overconfidence and underconfidence – give a more honest picture. And ultimately, business value or application utility matters in evaluations: the metric should reflect the actual decisions, costs, and consequences of the system's outputs.
Lessons from industry confirm how much can go wrong. Booking.com, the world's largest online travel platform, published a landmark analysis of around 150 successful customer-facing machine learning applications, validated through rigorous randomised controlled trials across hundreds of millions of users [6]. It’s one of the most honest accounts of what actually happens when machine learning meets the real world at scale. Their main conclusion was striking: an iterative, hypothesis-driven process, coupled with insights from other disciplines, was what made those 150 models succeed – not model performance alone. They documented why. Optimizing a proxy metric too hard causes it to diverge from what you actually care about. And once a model's predictions start influencing user behavior, the assumptions under which it was trained no longer hold. Each of these failure modes is invisible if you only look at your validation score.
Closing the gap in validation is one of the core motivations behind Skore, an open source library my team at Probabl is building. We believe rigorous evaluations should be as easy as fitting models.
The takeaway
AI is about automation at scale. Data science is about reasoning carefully from your data, which is more likely than not messy, biased, incomplete, and never quite what you need.
Statistical thinking is the bridge for building trustworthy, production-ready models. It’s what lets you reason about uncertainty, detect biases in model errors and uncertainty, distinguish fixable errors from irreducible ones, notice when selection bias has corrupted your training data, and think clearly about causal questions that pure prediction cannot answer.
The work continues – in application utility, in selection bias, in causal inference, and in building the tools that make these practices accessible to every data science practitioner working with real data in the real world.
For more from Probabl
- Follow our latest updates on LinkedIn
- Subscribe to our monthly newsletter
- Check out over 100 tutorial videos on our YouTube account
- Level up your machine learning skills for free with Skolar
References
[1] Chen, L., Perez-Lebel, A., Suchanek, F.M., Varoquaux, G., Reconfidencing LLMs from the Grouping Loss Perspective. 2024. https://arxiv.org/abs/2402.04957
[2] YAGO is a large knowledge base with general knowledge about people, cities, countries, movies, and organizations. https://yago-knowledge.org/
[3] Meelis Kull and Peter Flach. 2015. Novel decompositions of proper scoring rules for classification: Score adjustment as precursor to calibration. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2015, Porto, Portugal, September 7-11, 2015, Proceedings, Part I 15. Springer.; Alexandre Perez-Lebel, Marine Le Morvan, and Gael Varoquaux. 2023. Beyond calibration: estimating the grouping loss of modern neural networks. In The Eleventh International Conference on Learning Representations. https://arxiv.org/abs/2210.16315
[4] Sébastien Melo, Gaël Varoquaux, Marine Le Morvan. Epistemic Uncertainty Quantification to Improve Decisions From Black-Box Models. Fourteenth International Conference on Learning Representations, Apr 2026, Rio de Janeiro, Brazil. https://hal.science/hal-05393027v2/file/ICLR_2026_Camera_ready.pdf ; Alexandre Perez-Lebel, Marine Le Morvan, and Gael Varoquaux. 2023. Beyond calibration: estimating the grouping loss of modern neural networks. In The Eleventh International Conference on Learning Representations. https://arxiv.org/abs/2210.16315
[5] Sayash Kapoor, Arvind Narayanan, Leakage and the reproducibility crisis in machine-learning-based science, Patterns, Volume 4, Issue 9, 2023, 100804, ISSN 2666-3899, https://doi.org/10.1016/j.patter.2023.100804. https://www.sciencedirect.com/science/article/pii/S2666389923001599
[6] Lucas Bernardi, Themistoklis Mavridis, and Pablo Estevez. 2019. 150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '19). Association for Computing Machinery, New York, NY, USA, 1743–1751. https://doi.org/10.1145/3292500.3330744